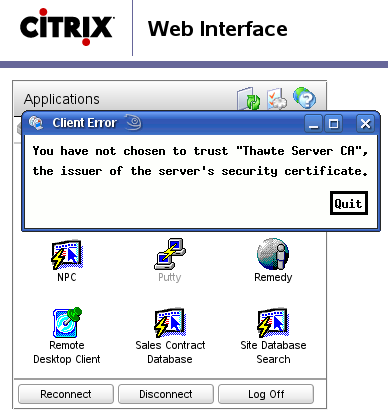
Let’s put two things together today…
- The BusPirate is the ultimate tinkerers’ tool that makes the SPI, I2C, 1-Wire, UART, JTAG and some other low-level protocols available to an ordinary PC equipped with a serial or USB port. That way a PC can talk to many digital electronic components, from temperature sensors through microcontrollers and memories to I/O devices like LCD displays or ethernet interfaces.
- Uploading a firmware to an Atmel AVR microcontroller (MCU) is possible through many different ways, with the most common and universal probably being ICSP — In Circuit System Programming. In essence ICSP is an SPI-based protocol, where the programmer sends special programming commands to the AVR chip along with data to be written to the flash memory. In most cases the MCU doesn’t even need to be removed from its circuit first.
- So the AVR can be programmed using SPI and the BusPirate can talk SPI, therefore the BusPirate can program AVRs, correct?
Yes, of course it can! All you need is a recent enough avrdude — either the current SVN checkout or avrdude 5.7 once it is released.

BusPirate with 2 independent AVRs.
AVRdude with BusPirate
Programming one AVR is a breeze, let’s have an example of ATtiny2313. Connect BusPirate to the IC like this:
| GND |
GND |
10 |
| +5V or +3.3V |
Vcc |
20 |
| CS |
RESET |
1 |
| MOSI |
MOSI |
17 |
| MISO |
MISO |
18 |
| SCL/CLK |
SCK |
19 |
It is possible, although not required, to power the chip from the BusPirate during programming. Even if the BP is not used as a Vcc supply for AVR their GNDs should still be interconnected.
All right, the ultracomplex “circuit” is ready to go. It’s time to test if it works…
.../attiny2313/test $ avrdude -p attiny2313 -c buspirate
Detecting BusPirate...
**
** Bus Pirate v1a
** Firmware v3.0
** DEVID:0x0447 REVID:0x3003 (A3)
** http://dangerousprototypes.com
**
BusPirate: using BINARY mode
avrdude: AVR device initialized and ready to accept instructions
Reading | ################################################## | 100% 0.02s
avrdude: Device signature = 0x1e910a
avrdude: safemode: Fuses OK
avrdude done. Thank you.
avrdude was able to read the device signature so the connection apparently works. Now it’s time to run avrdude with -U flash:w:project.hex to actually flash the firmware in.
One … two … three AVRs!
Any ICSP programmer can program one chip at a time. However the BusPirate goes a step further — we can connect up to 3 independent AVRs to a single BP and without any re-wiring program them. Each with a different firmware of course.
How come? The programmer grabs AVR’s attention by pulling its RESET pin Low. Check again the table above: BP’s CS (Chip Select) is connected to AVR’s RESET — once CS->RESET signal goes down (and stays down) the AVR is ready to accept SPI programming commands. However the BusPirate also has an AUX output pin that is independent on CS. If we add one more AVR to the picture with the same MISO, MOSI and CLK setup, but with its RESET connected to BP’s AUX instead of CS we’re instantly able to program either of the two chips because avrdude can be ordered to pull down AUX instead of CS using -x reset=aux parameter.
.../at90usb162/test $ avrdude -p at90usb162 -c buspirate -x reset=aux
Detecting BusPirate...
[...]
avrdude: Device signature = 0x1e9482
avrdude: safemode: Fuses OK
Talking to the other AVR works as well and its signature (different to the first one) has been read.
I also have an older BusPirate “clone” from Fundamental Logic — the hardware revision is v1a which is the only one that has one additional pin — AUX2. Obviously you can now add a 3rd AVR into the circuit and use avrdude -x reset=aux2 for its programming.
… four … five … six … seven AVRs!
What? Is there a BusPirate with 7 AUX’es?! No, there is not. However we can command avrdude not only to pull down either CS or AUX or AUX2, we can tell it to pull down, say CS and AUX2, while leaving AUX high: avrdude -x reset=cs,aux2. So what? Well then we can use a simple 3-bits to 1-of-8 decoder (for example 74HCT138), connect CS, AUX and AUX2 to its address inputs and use the 1-of-8-is-Low outputs for selecting the AVR to talk to. That would give us access to up to 7 independent AVRs in a single circuit with a single BusPirate (v1a only though). Why 7 and not all 8? Figure that out for a homework 
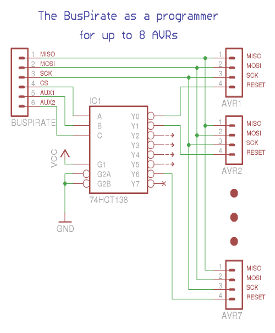
BusPirate with 3-bits to 1-of-8 decoder.
Only one output [Y0..Y7] is low at any time.
The same approach can be used to program three AVRs from a newer BusPirates without AUX2 output. Simply get a 2-bits to 1-of-4 decoder (for example 74HCT155) and, again, as a homework think of why we can only attach 3 AVRs and not all four
Decoupling
There is a little catch though. If all the AVRs don’t belong to the same design they should not be interconnected through SPI lines either. For example I’ve got ATtiny2313 and AT90USB162 on my breadboard but they do different things — the ATtiny is a temperature display with a SPI-connected sensor, while the AT90 has an ENC28J60 ethernet interface attached to its SPI pins. These two SPI buses are totally independent and we can’t simply connect all the MISOs and MOSIs together. We need to decouple them from each other and only pass the BusPirate SPI through to a single chip at a time. How? Using a 3-state bus buffer, for example 74HCT244. Since it’s got 3-state outputs it is virtually non-existent on the SPI bus unless active. A RESET Low signal coming from BusPirate’s CS or AUX or from the 1-of-N decoder activates the outputs of one of the 4-line gates and enables passing the SPI traffic between the BusPirate and the selected AVR. No other AVR will notice that one of these little silicon guys is being programmed. Huh? All right, here’s the schema
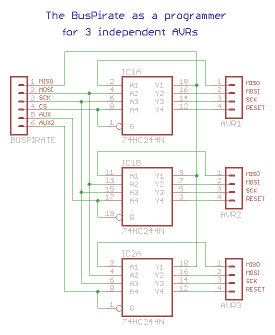
Decoupling the BusPirate from AVRs
to prevent interference with normal SPI traffic.
Etc…
A few days ago Ian, the author of BusPirate, announced the availability of STK500 AVR programmer firmware for the BusPirate hardware. I haven’t had a time to give it a try yet. I expect it may be somewhat faster comparing to avrdude -c buspirate. On the other hand it probably doesn’t support more than one concurrently connected chip — a feature for which I’m keen to sacrifice some programming speed.
The rumours go that there is one more BusPirate firmware on the way — a Microchip PIC programmer. I can’t wait to see that in action. And don’t forget the original BP firmware that can do a lot more than just programming microcontrollers. Sadly there doesn’t seem to be a dedicated, well structured BusPirate project website — you’re left to gather the information scattered throughout the BusPirate blog to find out all the details.
BusPirate is truly one of the must-have tools for anyone working with microcontrollers and related low-level communication protocols. It’s incredible how much functionality can be found in a $30 gadget.